Evite el ruido y preserve el contexto
Esencialmente, se trata de desglosar contenido de texto grande en partes manejables para optimizar la relevancia del contenido que obtenemos de una base de datos vectorial utilizando LLM.
Esto me recuerda a la búsqueda semántica. En este contexto, indexamos documentos llenos de información específica del tema.
Si nuestra segmentación se hace correctamente, los resultados de la búsqueda se alinean bien con lo que el usuario está buscando. Pero si nuestros segmentos son demasiado pequeños o demasiado gigantes, podríamos pasar por alto contenido importante o devolver resultados menos precisos. Por lo tanto, es crucial encontrar ese punto dulce para el tamaño del segmento para asegurarnos de que los resultados de la búsqueda sean precisos.
OpenAIEmbeddings
La clase OpenAIEmbeddings es una envoltura alrededor de la API de OpenAI para generar incrustaciones de lenguaje. Proporciona una forma de utilizar los servicios de la API, ya sea a través del servicio OpenAI predeterminado o a través de un punto final de Azure.
Aquí hay algunos aspectos destacados e ideas sobre los componentes clave de la clase OpenAIEmbeddings, según se describe en esta documentación:
- Inicialización: Una instancia de
OpenAIEmbeddingsse inicializa con una clave API de OpenAI. La clave se puede pasar como un parámetro nombrado al constructor (openai_api_key="mi-api-key"), o se puede establecer como la variable de entornoOPENAI_API_KEY. - Soporte de Azure: Esta clase también admite el uso de la API de OpenAI a través de los puntos finales de Microsoft Azure. Si está utilizando Azure, necesita establecer varias variables de entorno (
OPENAI_API_TYPE,OPENAI_API_BASE,OPENAI_API_KEY, yOPENAI_API_VERSION). ElOPENAI_API_TYPEdebe ser ‘azure’ y el resto debe corresponder a las propiedades de su punto final de Azure. - Soporte de Proxy: También se menciona la variable de entorno
OPENAI_PROXY, que se usaría para establecer un proxy para sus llamadas a la API, si es necesario. - Métodos de la clase: La clase proporciona dos métodos principales:
embed_documents(texts: List[str], chunk_size: Optional[int] = 0) → List[List[float]]: Este método genera incrustaciones para un lote de textos. Le pasa una lista de cadenas y, opcionalmente, un tamaño de segmento (que establece la cantidad de textos a incrustar por l ote). Devuelve una lista de listas de flotantes, donde cada lista interna es la incrustación de un solo texto.
embed_query(text: str) → List[float]: Este método genera una incrustación para un solo texto. Le pasa una cadena y devuelve una lista de flotantes como la incrustación. - Campos configurables: La clase también tiene tres campos configurables:
chunk_size,max_retries, yrequest_timeout. Estos campos le permiten personalizar el tamaño del lote para la generación de incrustaciones, el número máximo de reintentos al generar incrustaciones, y el tiempo de espera para la solicitud de la API, respectivamente.
En general, la clase OpenAIEmbeddings parece ser una herramienta útil y flexible para trabajar con la API de incrustaciones de lenguaje de OpenAI en Python, incluyendo características avanzadas como lotes, reintentos y soporte para puntos finales de OpenAI y Azure.
Agentes Conversacionales con Conocimiento
Ves, estos agentes utilizan segmentos incrustados para formar un contexto basado en conocimiento, que es crucial para proporcionar respuestas precisas. Sin embargo, el tamaño de nuestros segmentos es importante aquí. Un segmento que es demasiado grande podría no encajar dentro del contexto, especialmente considerando el límite de tokens que tenemos al enviar solicitudes a un proveedor de modelos externos como OpenAI. Por lo tanto, necesitamos proceder con cuidado con los tamaños de segmentos aquí.
Estrategias de Segmentación
Podemos seguir varias estrategias de segmentación, pero el truco está en entender tu caso de uso específico y elegir el enfoque correcto que ofrece un buen equilibrio entre el tamaño y el método.
Quiero centrarme en hablar de cómo incrustamos contenido corto y largo.
Cuando incrustamos una oración, el vector resultante se enfoca en el significado específico de esa oración. Pero cuando incrustamos segmentos más grandes como párrafos o documentos enteros, el vector considera el contexto más amplio, las relaciones entre las oraciones y los temas dentro del texto. Es más rico pero puede introducir ruido o diluir puntos clave.
La longitud de la consulta es otro aspecto fascinante. Las consultas cortas podrían coincidir bien con las incrustaciones a nivel de oración, mientras que las más largas que buscan un contexto más amplio podrían resonar más con las incrustaciones a nivel de párrafo o documento.
Varios factores pueden influir en nuestra elección de estrategia de segmentación:
Necesitamos considerar el contenido que estamos indexando, el modelo de incrustación, la complejidad de las consultas de usuario esperadas y cómo se utilizarán los resultados en nuestra aplicación. Todos estos factores ayudarían a afinar nuestra estrategia de segmentación.

Existen diferentes métodos de segmentación para explorar también:
- De tamaño fijo
- Consciente del contenido
- Recursiva
- Especializada



Mientras que la segmentación de tamaño fijo es el enfoque más común y directo, otros métodos como la segmentación consciente del contenido y la segmentación especializada pueden aprovechar la naturaleza y la estructura del contenido, respectivamente.
Descubrir el mejor tamaño de segmento para tu aplicación puede ser un desafío. Requiere:
Preprocesamiento de datos
- Seleccionando un rango de tamaños de fragmentos para probar.
- Evaluando iterativamente el rendimiento hasta que encuentres el tamaño de fragmento óptimo.
Y recuerda, el «mejor» tamaño de fragmento puede variar de una aplicación a otra.
Al final, la fragmentación es sencilla la mayoría de las veces, pero puede complicarse dependiendo de tus necesidades específicas.
No hay una solución que sirva para todos
El mejor consejo que puedo dar es que entiendas profundamente tu caso de uso y experimentes hasta que encuentres el enfoque correcto.
Módulo text2vec-openai de Weaviate
Una herramienta emocionante y versátil que combina el poder de los modelos de lenguaje de OpenAI con la infraestructura de datos de Weaviate.

El uso de este módulo implica una API de terceros y puede generar costos adicionales, por lo que siempre debes consultar la página de precios de OpenAI antes de escalar tus operaciones.
Lo que distingue al módulo text2vec-openai es su interacción fluida con OpenAI o Azure OpenAI. Con esta flexibilidad, puedes utilizar los modelos de última generación de OpenAI para representar eficazmente tus objetos de datos dentro de Weaviate o Azure.
Weaviate facilitó el trabajo con ambos proveedores de servicios, solo asegúrate de seguir las instrucciones adecuadas para el proveedor que elijas.
Te alegrará saber que el módulo viene listo para usar y preconfigurado en Weaviate Cloud Services.

Si estás usando Weaviate open source, puedes habilitarlo fácilmente en tu archivo de configuración, como docker-compose.yaml, y establecerlo como tu módulo vectorizador pred eterminado.

Aquí tienes un breve ejemplo de cómo configurarlo:
version: '3.4'
services:
weaviate:
image: semitechnologies/weaviate:1.19.6
restart: on-failure:0
ports:
- "8080:8080"
environment:
QUERY_DEFAULTS_LIMIT: 20
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: "./data"
DEFAULT_VECTORIZER_MODULE: text2vec-openai
ENABLE_MODULES: text2vec-openai
OPENAI_APIKEY: sk-foobar # Opcional; puedes proporcionar la clave en tiempo de ejecución.
AZURE_APIKEY: sk-foobar # Opcional; puedes proporcionar la clave en tiempo de ejecución.
CLUSTER_HOSTNAME: 'node1'
...Para la configuración, puedes integrar tu clave de OpenAI o Azure API directamente en la configuración del entorno o proporcionarla en tiempo de ejecución.
Con nuestro módulo, puedes ajustar fácilmente el modelo y comportamiento del vectorizador a través de tu esquema.
Aquí te mostramos cómo podrías definir una clase de documento con las configuraciones de OpenAI:
{
"classes": [
{
"class": "Document",
"description": "Una clase llamada documento",
"vectorizer": "text2vec-openai",
"moduleConfig": {
"text2vec-openai": {
"model": "ada",
"modelVersion": "002",
"type": "text"
}
},
}
]
}Operadores de búsqueda vectorial GraphQL
El módulo text2vec-openai de Weaviate también permite operadores de búsqueda vectorial GraphQL, proporcionando una clave de API durante la consulta si no está establecida en la configuración.
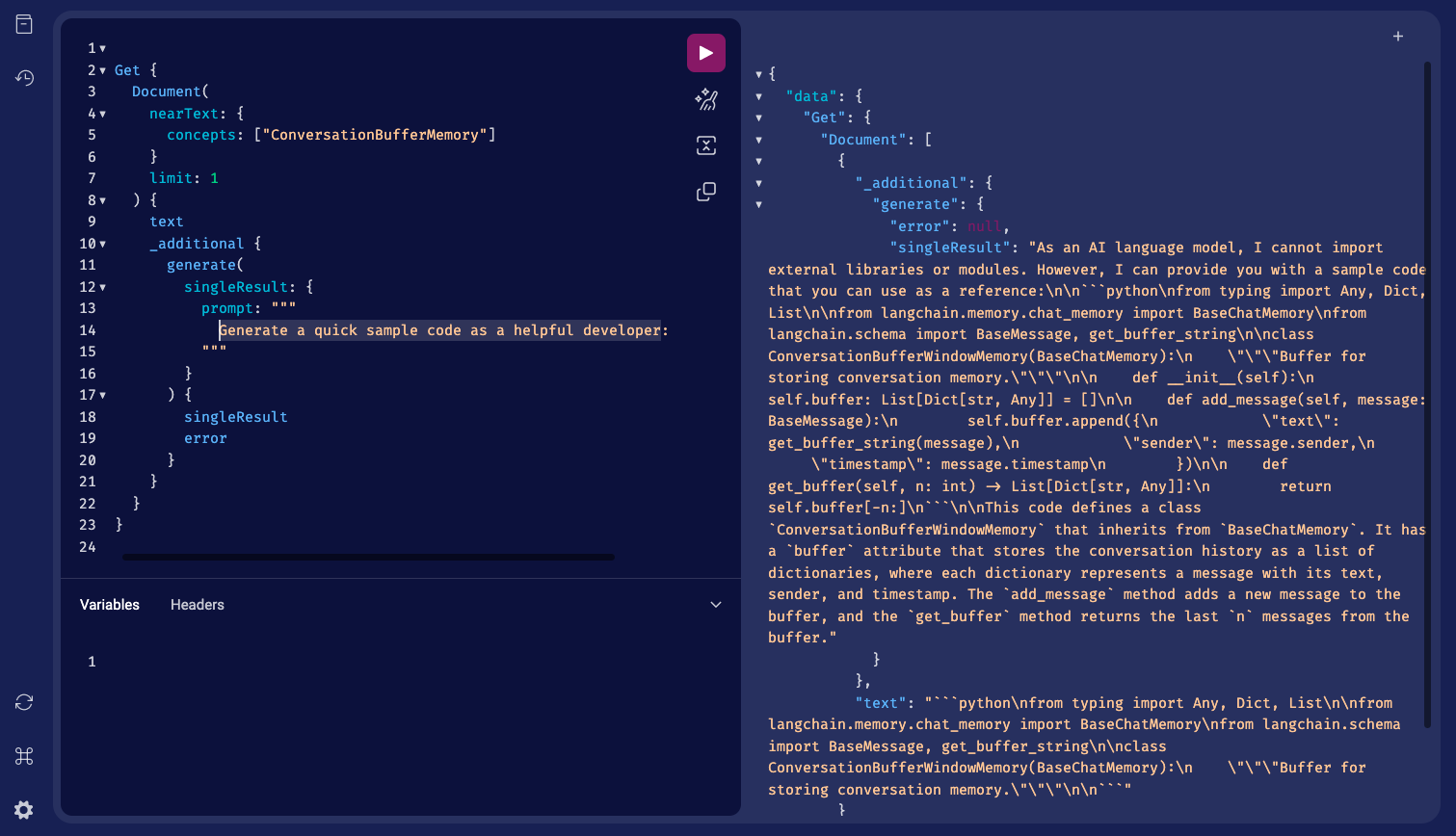
Por ejemplo, así es cómo pasarías la clave a través del encabezado HTTP:
X-OpenAI-Api-Key: TU-CLAVE-DE-API-OPENAI
X-Azure-Api-Key: TU-CLAVE-DE-API-AZURERecuerda que tienes la libertad de elegir entre varios modelos de OpenAI para los embeddings de documentos o códigos, como ‘ada‘, ‘babbage‘, ‘curie‘, y ‘davinci‘.
Recomiendo tener en cuenta los límites de tasa de OpenAI cuando utilices tu clave de API.
Si alcanzas tu límite, recibirás un mensaje de error de la API de OpenAI.
Y por supuesto, Weaviate tiene herramientas para ayudar a gestionar estos límites de tasa, como la capacidad de regular la importación dentro de tu aplicación, como se ilustra en los ejemplos de clientes de Python y Java.
¿Qué esperas? Empieza a utilizar el módulo text2vec-openai de Weaviate y desbloquea el mundo de la representación de datos mejorada con el poder de OpenAI.