The /goal Feature
A Practical Guide for Claude Code, Codex, and Hermes Agent
The
/goalcommand (a.k.a. goal mode or persistent goals) is one of the most important 2026 advancements in autonomous AI agents. It turns one-shot prompts into fire-and-forget, judge-verified workflows.Instead of you babysitting the loop, you declare a durable objective with a verifiable end state. The agent then plans → acts → observes → iterates across many turns (sometimes hours) until an independent judge model confirms the goal is met — or you
/pauseor/clearit.
It first shipped in OpenAI Codex, then landed in Hermes Agent, and arrived in Claude Code.
Mental model: how /goal actually works
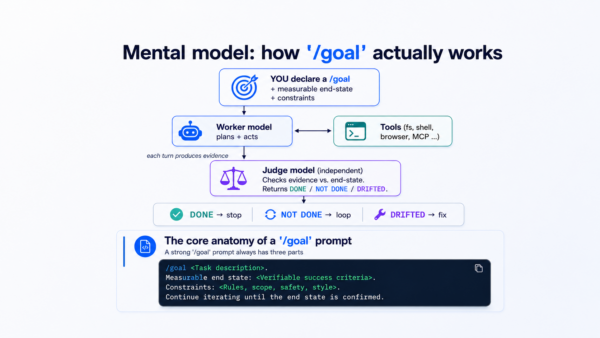
The judge being a separate model from the worker is the key innovation: it prevents the worker from declaring victory too early and prevents it from spinning forever.
| Component | What it is | Good ✅ | Bad ❌ |
|---|---|---|---|
| Goal / Task | A clear, actionable objective written in the imperative. | «Migrate all v1 API calls to v2.» | «Make the API better.» |
| Measurable end state | The judge’s checklist. Observable, binary, machine-checkable when possible. | «Command npm test exits 0; grep for /api/v1 in src/ returns no matches.» | «It should work.» |
| Constraints | Boundaries: scope, style, safety, non-goals. | «Only edit src/ and tests/. No public API breakage. Conventional Commits.» | (none — agent will drift) |
Why this works: The judge evaluates the end state independently every iteration. This stops both premature completion («looks good to me!») and endless spinning («just one more refactor…»).
Common subcommands
These are consistent across the three tools, with minor naming differences:
| Subcommand | What it does |
|---|---|
/goal status | Show progress, last judge verdict, remaining criteria. |
/goal pause | Freeze the loop. State is preserved. |
/goal resume | Continue from the last checkpoint. |
/goal clear | Stop and reset. Use this when you need to refine the goal itself. |
/goal log (Hermes) | Dump the full action+judge transcript. |
/goal export (Codex) | Save the run as a replay artifact. |
Tool-by-tool deep dive
Claude Code
- Strengths: Strong terminal & project context. Tight integration with Skills (code.claude.com/docs/en/slash-commands) — you can define a
goalskill that pre-injects your project’sCLAUDE.md, run lints and tests as bash blocks, and pre-approve tools viaallowed-tools. - Scope: Session-scoped by default. Survives
/compactif the goal skill is re-attached. - Best for: Repo-bound work where success = «tests pass + diff is clean.»
- Pattern: Pair
/goalwith a forked Plan or Explore subagent for the planning step, then ageneral-purposeagent for execution.
# .claude/skills/goal/SKILL.md (sketch)
---
name: goal
description: Run a long-form goal with judge-verified completion. Use when the user types /goal.
allowed-tools: Bash(npm test) Bash(git *) Read Edit Grep
---
Run this goal until the judge confirms the end state.
Project context:
!`cat CLAUDE.md`
Current diff:
!`git diff HEAD`
Goal: $ARGUMENTSCodex
- Strengths: Long-running CLI workflows with persisted state.
/goalintegrates with AGENTS.md, Hooks, and Subagents. Excellent in Non-interactive mode for CI. - Scope: Goals can outlive the terminal (resumable from the Codex App / App Server).
- Best for: Migrations, refactors, multi-PR campaigns, scheduled CI repairs.
- Pattern: Combine with the GitHub Action so a goal can open PRs, wait for CI, read the result, and iterate without you.
Hermes Agent
- Strengths: Persistent across sessions, Kanban view of in-flight goals, auto-generated Skills that grow with the agent, Telegram/Discord/Slack/WhatsApp surfaces, and 5 sandbox backends (local, Docker, SSH, Singularity, Modal). See hermes-agent.nousresearch.com.
- Scope: Truly long-lived — a goal can run for days while you check in from your phone.
- Best for: Background research, monitoring + maintenance loops, orchestrating other agents (Claude Code & Codex sessions) via subagents.
- Pattern: Use Hermes as the orchestrator that spawns Claude Code / Codex workers per Kanban card.
Examples by category
1. Research
/goal Conduct a comprehensive review of retrieval-augmented generation (RAG)
techniques published in 2025–2026.
Measurable end state:
- File `report.md` exists with sections: Key Papers, Benchmarks, Limitations,
Comparison Table, Recommendations.
- At least 8 distinct sources, each with a working URL and one direct quote.
- Comparison table covers ≥5 techniques across ≥4 dimensions.
- Ends with exactly 3 actionable recommendations.
- Word count between 1500 and 3000.
Constraints:
- Use only publicly available sources via the browser tool.
- Cite every factual claim. Flag uncertainties with "⚠ unverified".
- No fabricated authors, years, or numbers.
- Stop and ask if a paywalled source blocks a key claim.
Continue iterating until the end state is confirmed.Expected behavior: the agent searches → reads → drafts → re-reads → fills gaps → judge verifies citations and structure. Hermes is especially strong here because it can leave the loop running and notify you on Telegram when done.
2. Local files
/goal Update all deprecated v1 API calls across the codebase to the new v2
endpoints.
Measurable end state:
- `rg "/api/v1" src/ tests/` returns 0 matches.
- `npm test` exits with code 0.
- `CHANGELOG.md` has a new entry under "## Unreleased" describing the migration.
- Commits are split logically (one per module) and follow Conventional Commits.
Constraints:
- Only modify files under `src/` and `tests/`.
- No breaking changes to publicly exported symbols.
- Preserve existing comments and formatting (run prettier after edits).
- If a v2 endpoint is missing, open `MIGRATION_BLOCKERS.md` and stop.
Continue iterating until the end state is confirmed.Why Hermes shines: persistent memory + auto-generated Skills means once it learns how you migrate one module, the second one is faster.
3. Visuals (UI / design / generation)
/goal Build a modern, responsive landing page for an AI productivity tool.
Measurable end state:
- Files `index.html` and `styles.css` exist and are referenced from each other.
- Page contains: hero (headline + sub + CTA), 6-item features grid, footer.
- Lighthouse (run `npx lighthouse http://localhost:8080 --quiet`) reports
Performance ≥90, Accessibility ≥95, Best Practices ≥90.
- Manual breakpoint check at 375px, 768px, 1280px shows no horizontal scroll
(use the browser tool screenshots stored in /screenshots).
- Dark mode is the default; a `prefers-color-scheme: light` override exists.
Constraints:
- Tailwind via CDN OR vanilla CSS — no build step.
- No external JS dependencies.
- Total page weight under 200 KB gzipped.
- Match brand palette: primary #6366F1, accent #22D3EE.
Continue iterating until the end state is confirmed.For pure image generation (e.g., logos), the same pattern works — just make the end state describe what must be visible in the final image and have the judge inspect via vision.
4. Coding
/goal Implement user authentication with JWT access + refresh tokens.
Measurable end state:
- Endpoints `/auth/register`, `/auth/login`, `/auth/refresh`, `/auth/logout`
match the contract in `docs/API.md`.
- `pytest tests/auth/ -q` exits 0 with ≥90% coverage on `app/auth/`.
- `bandit -r app/auth/` reports no HIGH severity issues.
- No secrets are hardcoded (`gitleaks detect --no-git` exits 0).
- README has a "Authentication" section with curl examples.
Constraints:
- Follow PEP8; type hints everywhere; pydantic v2 models for I/O.
- Reuse existing SQLAlchemy session and FastAPI app factory.
- Refresh tokens stored hashed; rotate on use.
- Do NOT touch billing or admin modules.
Continue iterating until the end state is confirmed.This is the canonical sweet spot for /goal: tests + lints + security checks form an objective, machine-verifiable end state.
Pro tips
- Define «done» ruthlessly. Vague goals fail. Tie completion to tests, files, regex matches, exit codes, or numeric thresholds — anything the judge can verify deterministically.
- Start small, then scale. Test with a 5-minute goal before launching a 5-hour one. Watch with
/goal status. - Budget turns and time. Most agents have implicit caps (Hermes ~20 turns/segment). Add explicit ones: «max 15 iterations; if not done, write
BLOCKERS.mdand stop.» - Combine tools. Use Hermes as orchestrator to dispatch Claude Code or Codex sessions across a Kanban board. Each card is its own
/goal. - Checkpoints & safety. Lean on Hermes checkpoints/rollback and Codex/Claude diff review. Always commit before launching a long goal so you can
git reset --hardcleanly. - Iterate on the goal itself. If the agent drifts twice,
/goal clear, then add a new constraint that targets the failure mode (e.g., «do not modifypackage.json«). - Cost awareness. Long runs burn tokens. Set spend limits in your provider console. Hermes can throttle via its sandbox config.
- Trust the independent judge. Don’t ask the worker to self-grade — let the separate judge model do its job.
- Prime context first. Before
/goal, hand the agent yourCLAUDE.md,AGENTS.md, repo READMEs, or a Hermes Skill. Cheap upfront context saves expensive mid-loop confusion. - Make the end state include negative checks. «…and
rg "TODO|FIXME" src/ | wc -lis unchanged or lower.» Negative checks catch sneaky regressions. - Use VCS as your safety net. Branch per goal:
git switch -c goal/<short-name>. Squash-merge when the judge confirms success. - Log the judge verdicts. Save them to a file. They’re gold for refining future goals.
Advanced prompt structure (layered template)
For complex, multi-hour goals, use this layered format:
/goal <One-sentence high-level objective>.
## Breakdown
1. <Step 1 — what to investigate / produce>
2. <Step 2 — what to implement>
3. <Step 3 — what to verify>
## Measurable end state (the judge will verify exactly these)
- [ ] Command `<cmd>` exits 0.
- [ ] File `<path>` exists and contains `<regex or string>`.
- [ ] Metric `<name>` ≥ `<threshold>` per `<measurement command>`.
- [ ] Artifact: `<path>` matches the structure in `<schema/example>`.
## Success proof (what the agent must show me)
- Pasted output of the verification commands.
- A short diff summary per affected module.
- Updated `CHANGELOG.md` entry.
## Constraints & non-goals
- MUST: <e.g., keep public API stable, run formatter after each edit>.
- MUST NOT: <e.g., delete migrations, touch /infra, call paid APIs>.
- Style: <e.g., Conventional Commits, PEP8, 2-space indent>.
- Scope: <e.g., only files under src/auth/ and tests/auth/>.
## Verification loop
After each major change:
1. Run `<test cmd>` and `<lint cmd>`.
2. Append a one-line summary to `.goal/journal.md`.
3. Only declare done when ALL end-state checks pass on a clean run.
## Stop conditions
- Hard stop after 20 iterations — write `BLOCKERS.md` instead of guessing.
- Stop and ask if a destructive action is required (drop table, force push, …).Anti-patterns
| Anti-pattern | Why it fails | Fix |
|---|---|---|
| «Make the code better.» | No measurable end state. | Tie to tests, coverage %, or specific refactors. |
| End state = «agent says it’s done.» | Worker grades itself. | Use commands/regex the judge can re-run. |
| No file/scope constraint. | Agent edits package.json, CI, secrets. | Whitelist directories. |
| Goal includes 7 unrelated tasks. | Judge can’t verify; agent thrashes. | Split into 7 goals on a Kanban (Hermes). |
| No stop condition. | Burns tokens forever. | «Max N iterations, then write BLOCKERS.md.» |
| Goal launched on dirty working tree. | Hard to roll back. | Always branch + commit first. |
Quick reference cheat sheet
/goal <task>. Measurable end state: <criteria>. Constraints: <rules>. Iterate until confirmed.
/goal status # progress + last judge verdict
/goal pause # freeze
/goal resume # continue
/goal clear # stop & reset| Tool | Best at | Surface |
|---|---|---|
| Claude Code 2.1.139+ | Repo-scoped, test-driven work; rich Skills + hooks | Terminal, IDE |
| Codex | Long CLI runs, CI/PR campaigns, GitHub Action | CLI, App, Action |
| Hermes Agent v0.13+ | Days-long autonomy, Kanban, multi-channel, orchestrator | Telegram/Discord/Slack/WhatsApp/CLI |
Field signal: what the community is saying (May 2026)
Two recent posts on X corroborate the orchestration pattern this guide recommends. Both are reproduced here verbatim from screenshots so you can judge the source for yourself.
1. WorldofAI (@intheworldofai) — Hermes Agent changelog
Hermes Agent is evolving FAST. In just the past week, Nous Research added:
• A full WebUI/Desktop App
• Background Computer Use on macOS
• Multi-agent orchestration
• Hermes Kanban upgrades
• Lightpanda browser backend support
• Qwen3.6-Plus FREE in Nous Portal
• Better autonomous workflows
• Persistent long-term memory systemsHermes is starting to feel less like an AI tool and more like a true open-source Agentic AI Operating System.
You can set up the Hermes Agent dashboard at 127.0.0.1:9118/kanban with columns TRIAGE / TODO / READY / IN PROGRESS / BLOCKED / DONE and cards labeled CODEX GOAL, CLAUDE CODE GOAL, and HERMES GOAL.
Cross-check vs. this guide:
| Claim in tweet | Status vs. this doc |
|---|---|
| Multi-agent orchestration in Hermes | ✅ Matches the «Hermes as orchestrator» pattern in the deep dive. |
| Hermes Kanban + persistent memory | ✅ Matches «Kanban view of in-flight goals» and «persistent across sessions». |
| Background Computer Use on macOS | ⚠ Unverified — not covered in this guide; treat as a separate capability from /goal. |
| Lightpanda browser backend | ⚠ Unverified — not in the listed sandbox backends (local/Docker/SSH/Singularity/Modal). May be additive. |
| Qwen3.6-Plus free in Nous Portal | ⚠ Unverified — out of scope for /goal semantics. |
YouTube link youtu.be/Gx2joHxUhgg | ⚠ Not independently verified. |
2. Shubham Saboo (@Saboo_Shubham_) — three-agent /goal workflow (12 May 2026)
Codex
/goalbuilds it.Claude Code
/goalreview and refines it.Hermes
/goalmanages the orchestration and handoff.All tracked on a single Kanban Board and agents keep running in the loop.
You can set up Hermes Kanban with cards explicitly named CODEX GOAL: BUILD …, CLAUDE CODE GOAL: REVIEW …, and HERMES GOAL: … moving across columns.
Cross-check vs. this guide:
- ✅ Builder / Reviewer / Orchestrator role split is exactly the pattern recommended in Pro tips #4 («Use Hermes as orchestrator to dispatch Claude Code or Codex sessions across a Kanban board. Each card is its own
/goal.»). - ✅ «Agents keep running in the loop» matches the plan → act → observe → judge cycle in the Mental model.
Caveat: Both posts are community signal, not vendor documentation. Treat the bullet lists as roadmap-grade evidence, and verify version against the official changelogs (code.claude.com, developers.openai.com/codex, hermes-agent.nousresearch.com) before depending on a specific feature.
Bottom line: master the end-state definition and
/goalturns these agents from «smart autocompletes» into reliable, fire-and-forget collaborators. Update to the latest versions and try one small goal today.