From Kaggle to Ollama
Fine-Tuning Gemma 4 31B with Unsloth, Merging LoRA on RunPod, Exporting GGUF, and Running It Locally.
Local LLMs/SLMs as Legal Department Assistants
The true value of this workflow is not in the technical achievement alone, but in what it enables for real organizations. A legal department in Costa Rica can now run a specialized labor-code assistant directly on a consumer machine, a laptop or small office server, without sending queries to external APIs, without incurring per-request costs, and without exposing sensitive legal documents to third-party services. The model runs entirely offline. It can answer questions about the Código de Trabajo in Spanish, cite articles, and ground its responses in authentic legal text. This is the first Costa Rican Legal Code.

The same workflow—dataset curation, Kaggle training, RunPod merge and export, local Ollama deployment—can be repeated for other Costa Rican legal codes: the Civil Code, Commercial Code, Family Code, and others. Each would become its own offline assistant, tailored to a department’s specific legal domain, deployable on existing hardware, and free from external dependency.
This is how small, well-trained models become infrastructure.
Executive summary
This is a practical build log of an end-to-end fine-tuning experiment around Gemma 4 31B, Unsloth, Kaggle, RunPod, Hugging Face, GGUF, and Ollama.
The goal was to train a model on a Costa Rican legal dataset, specifically a JSONL dataset for the Código de Trabajo de Costa Rica, then turn the result into something usable locally through Ollama.
The workflow produced three important artifacts:
gemma_4_lora//workspace/gemma-4-codigo-trabajo-finetune//workspace/gemma-4-codigo-trabajo-gguf_gguf/gemma-4-31b-it.Q4_K_M.gguf
The final local Ollama model was created as:
codigo-trabajo-cr
Key project links:
- GitHub repository:
https://github.com/josoroma/codigo-trabajo-dagster-pipeline - Kaggle Notebook:
https://www.kaggle.com/code/josoroma/hackaton-gemma4-31b-text-legal-codigo-de-trabajo/edit - Hugging Face merged model:
https://huggingface.co/josoroma/gemma-4-codigo-trabajo-finetune - Hugging Face GGUF model:
https://huggingface.co/josoroma/gemma-4-codigo-trabajo-gguf
The main lesson is simple: training a LoRA, merging a LoRA, exporting GGUF, and loading the result in Ollama are four different workflows with four different bottlenecks.
Kaggle was enough for the training flow. RunPod A100 80GB was enough for the merge and GGUF export.
Ollama on Apple Silicon was enough to load and run the final Q4_K_M GGUF locally.
What this project was trying to build
The project started as a legal-domain fine-tune. The target behavior was a Spanish-language assistant specialized in the Código de Trabajo de Costa Rica.
The desired final flow was:
Costa Rican Labor Code dataset
↓
Kaggle + Unsloth fine-tuning
↓
LoRA adapter
↓
RunPod A100 merge
↓
Hugging Face-format merged model
↓
GGUF Q4_K_M export
↓
Ollama local modelThe important point is that the training output was not supposed to be the final Ollama model. The training output was the adapter. The rest of the work was about converting that adapter into something local inference tools can actually use.
Starting point: the Gemma 4 / Unsloth notebook
The initial notebook was based on the Gemma 4 / Unsloth hackathon flow and was titled:
gemma4-31b-text-legal-codigo-de-trabajo
The notebook contained the usual sections:
- Install Unsloth and dependencies.
- Load Gemma 4 31B with
FastModel. - Run basic text, vision, and audio demos.
- Add LoRA adapters.
- Prepare the dataset.
- Train with
SFTTrainer. - Save the LoRA adapter.
- Save a merged Hugging Face-format model.
- Export GGUF for llama.cpp / Ollama.
The notebook originally expected a generic demo dataset. For this project, the important change was replacing that stock dataset with a Costa Rican legal JSONL dataset.
Installing Unsloth in the notebook
The notebook installed Unsloth and its dependencies with this pattern:
%%capture
try:
import numpy, PIL
_numpy = f"numpy=={numpy.__version__}"
_pil = f"pillow=={PIL.__version__}"
except:
_numpy = "numpy"
_pil = "pillow"
!uv pip install -qqq \
"torch>=2.8.0" "triton>=3.4.0" {_numpy} {_pil} torchvision bitsandbytes \
unsloth "unsloth_zoo>=2026.4.6" transformers==5.5.0 torchcodec timmThis same dependency pattern mattered later on RunPod. A fresh RunPod container did not automatically have the exact Unsloth stack needed to reload the adapter, so the dependencies had to be installed again there.
Loading Gemma 4 31B on Kaggle
The notebook loaded the model through Unsloth:
from unsloth import FastModel
import torch
model, tokenizer = FastModel.from_pretrained(
model_name = "unsloth/gemma-4-31B-it",
dtype = None,
max_seq_length = 8192,
load_in_4bit = True,
full_finetuning = False,
device_map = "balanced",
)The important settings were:
model_name = "unsloth/gemma-4-31B-it"
max_seq_length = 8192
load_in_4bit = True
full_finetuning = False
device_map = "balanced"On Kaggle, the training notebook used two Tesla T4 GPUs. That was enough for the training flow, but it was not enough for the later reload, merge, and export workflow.
LoRA setup
The notebook used LoRA adapters so that the project did not need to full-fine-tune all model weights:
model = FastModel.get_peft_model(
model,
finetune_vision_layers = False,
finetune_language_layers = True,
finetune_attention_modules = True,
finetune_mlp_modules = True,
r = 8,
lora_alpha = 8,
lora_dropout = 0,
bias = "none",
random_state = 3407,
)This matched the project goal: a text-only legal assistant. Vision layers were disabled, while language, attention, and MLP modules were kept trainable through LoRA.
The dataset: Costa Rican Labor Code JSONL
The local training data was:
data/datasets/codigo_trabajo.jsonl
A typical row had this shape:
{
"instruction": "Explica en qué consiste el artículo 1 del Código de Trabajo.",
"input": "",
"output": "El artículo 1 establece que el Código de Trabajo tiene por objeto regular los derechos y las obligaciones que surgen entre patronos y trabajadores con motivo del trabajo, y que dicha regulación se inspira en los principios cristianos de Justicia Social.",
"source_quote": "El presente Código regula los derechos y obligaciones de patronos y trabajadores con ocasión del trabajo, de acuerdo con los principios cristianos de Justicia Social.",
"source_url": "https://www.pgrweb.go.cr/scij/Busqueda/Normativa/Normas/nrm_texto_completo.aspx?nValor1=1&nValor2=8045",
"law_code": "Código de Trabajo de Costa Rica",
"article": "1",
"chunk_id": "libro_None_titulo_PRIMERO_capitulo_PRIMERO_articulo_1",
"dataset_type": "article_explanation"
}The fields used for training were:
instruction
input
outputThe fields used for traceability were:
source_quote
source_url
law_code
article
chunk_id
dataset_typeThose traceability fields were important for auditing the dataset, even if the notebook did not inject all of them into every prompt.
Final status
cat > /workspace/merge_lora.py << 'EOF'
from unsloth import FastModel
from unsloth.chat_templates import get_chat_template
import os
LORA_PATH = "/workspace/gemma_4_lora"
OUT_PATH = "/workspace/gemma-4-codigo-trabajo-finetune"
print("LoRA exists:", os.path.exists(LORA_PATH))
print("LoRA files:", os.listdir(LORA_PATH))
model, tokenizer = FastModel.from_pretrained(
model_name=LORA_PATH,
dtype=None,
max_seq_length=8192,
load_in_4bit=True,
full_finetuning=False,
device_map="auto",
)
tokenizer = get_chat_template(tokenizer, chat_template="gemma-4-thinking")
print("Loaded model + adapter.")
print("Saving merged model...")
model.save_pretrained_merged(OUT_PATH, tokenizer)
print("Done:", OUT_PATH)
print("\nVerify shards exist:")
os.system(f"ls -lh {OUT_PATH}/model-*.safetensors")
EOF
---
cat > /workspace/export_gguf.py << 'EOF'
import os
os.environ["HF_HOME"] = "/workspace/hf_cache"
os.environ["TMPDIR"] = "/workspace/tmp"
os.makedirs("/workspace/hf_cache", exist_ok=True)
os.makedirs("/workspace/tmp", exist_ok=True)
from unsloth import FastModel
from unsloth.chat_templates import get_chat_template
LORA_PATH = "/workspace/gemma_4_lora"
OUT_PATH = "/workspace/gemma-4-codigo-trabajo-gguf"
print("LoRA exists:", os.path.exists(LORA_PATH))
model, tokenizer = FastModel.from_pretrained(
model_name=LORA_PATH,
dtype=None,
max_seq_length=8192,
load_in_4bit=True,
full_finetuning=False,
device_map="auto",
)
tokenizer = get_chat_template(tokenizer, chat_template="gemma-4-thinking")
print("Loaded model + adapter.")
print("Saving GGUF to:", OUT_PATH)
model.save_pretrained_gguf(
OUT_PATH,
tokenizer,
quantization_method="Q4_K_M",
)
print("Done:", OUT_PATH)
os.system(f"ls -lh {OUT_PATH}/*.gguf")
EOFThe project successfully trained a Gemma 4 31B LoRA adapter on Costa Rican Labor Code examples, merged that adapter into a Hugging Face-format model on RunPod A100 80GB, exported a Q4_K_M GGUF file through Unsloth and llama.cpp, uploaded the GGUF artifacts to Hugging Face, imported the Q4_K_M GGUF into Ollama, and ran the local model as codigo-trabajo-cr.
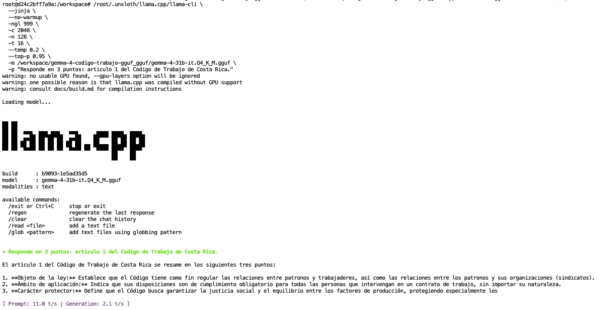
Ollama Prompt:
Actúa como un asistente legal especializado en el Código de Trabajo de Costa Rica.
Consulta únicamente el texto del Código de Trabajo de Costa Rica y responde con base en artículos específicos.
Caso:
"Mi jefe me despidió después de haber trabajado para él durante 5 años y no me ha reconocido ninguna liquidación, indemnización, preaviso, cesantía, vacaciones, aguinaldo ni otros derechos laborales. Quiero presentar mi caso ante el Ministerio de Trabajo."
Tarea:
1. Identifica los artículos del Código de Trabajo de Costa Rica que podrían servir para sustentar mi reclamo.
2. Explica brevemente qué protege o regula cada artículo.
3. Indica cómo podría usar cada artículo al presentar el caso ante el Ministerio de Trabajo.
4. Diferencia entre:
- despido con responsabilidad patronal,
- despido sin responsabilidad patronal,
- preaviso,
- auxilio de cesantía,
- vacaciones,
- aguinaldo,
- salario pendiente,
- carta de despido,
- carga de la prueba.
5. No inventes artículos ni doctrina.
6. Cita literalmente el fragmento relevante de cada artículo.
7. Si algún punto no está claramente establecido en el Código de Trabajo, responde: "No encontrado en el Código de Trabajo disponible."
8. No des asesoría legal definitiva; presenta la información como orientación para preparar una consulta ante el Ministerio de Trabajo.
Formato de respuesta:
- Resumen breve del caso.
- Tabla con: artículo, tema, cita literal, explicación práctica.
- Lista de documentos que debería llevar al Ministerio de Trabajo.
- Preguntas clave que debería hacerle al inspector laboral.
- Resumen final en un párrafo.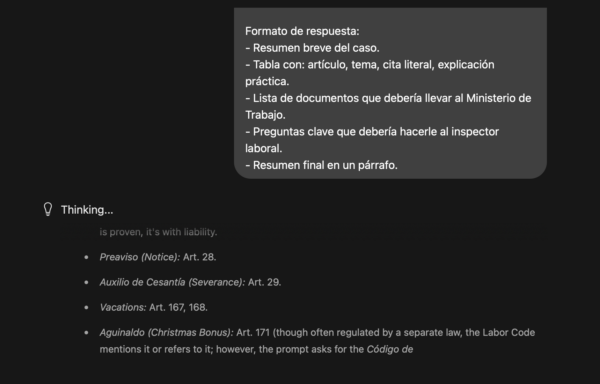
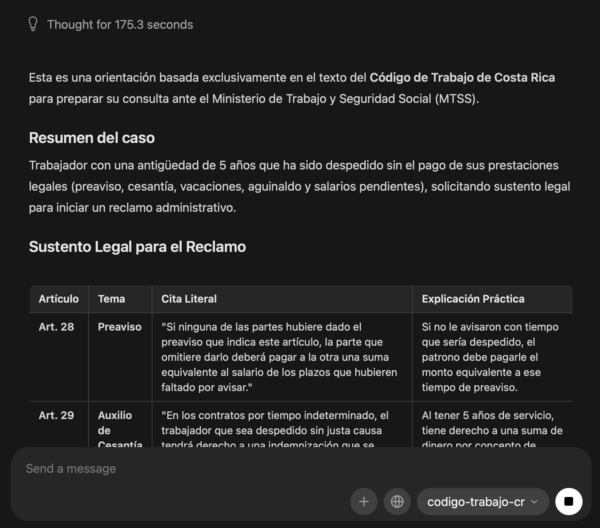
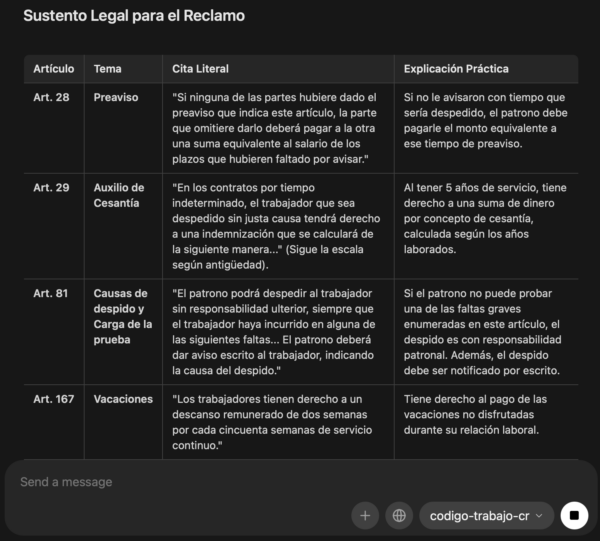

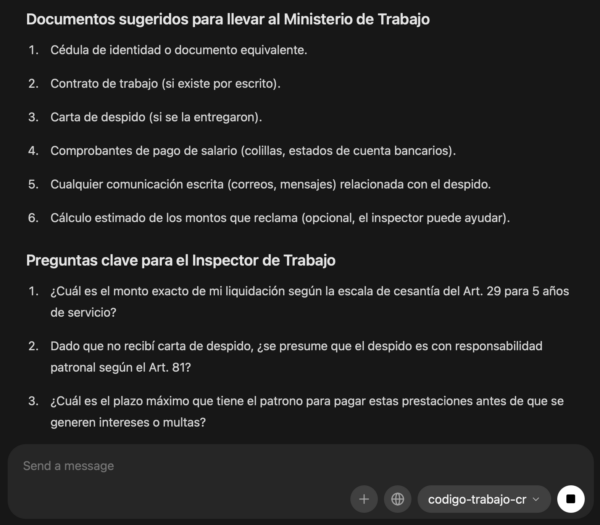
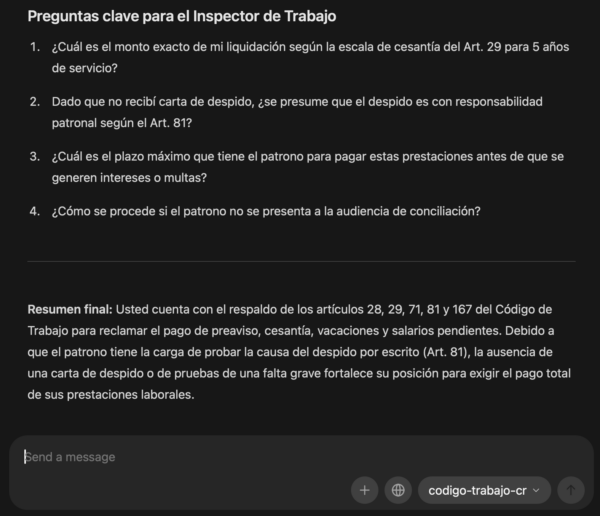
The remaining work is not basic model plumbing anymore. The next work is evaluation: test the model against article-specific questions, compare answers against source quotes, measure hallucination risk, and decide whether the dataset needs more examples, better source grounding, or stricter answer formatting.
This workflow started with a Kaggle/Unsloth fine-tune of Gemma 4 31B on a Costa Rican Labor Code JSONL dataset, saved the result as a LoRA adapter, moved the adapter to RunPod, merged it on an A100 80GB instance, exported Q4_K_M GGUF files, uploaded the artifacts to Hugging Face, and finally ran the model locally through Ollama as codigo-trabajo-cr. The build is no longer blocked on GGUF export or Ollama import; the next step is legal-answer evaluation and dataset quality control.